
- Hyung-Kwon Ko, KAIST
- Gwanmo Park, Seoul National University
- Hyeon Jeon, Seoul Nationl University
- Jaemin Jo, Sungkyunkwan University
- Juho Kim, KAIST
- Jinwook Seo, Seoul National University
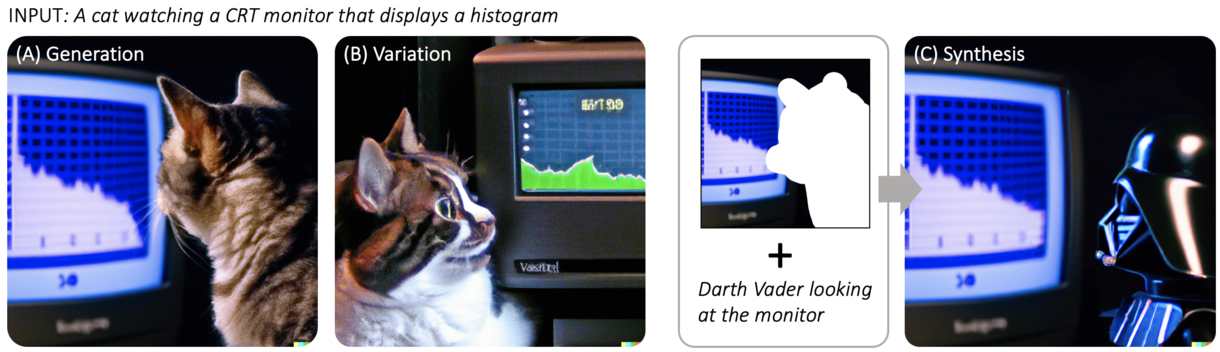
Large-scale Text-to-image Generation Models (LTGMs) (e.g., DALL-E), self-supervised deep learning models trained on a huge dataset, have demonstrated the capacity for generating high-quality open-domain images from multi-modal input. Although they can even produce anthropomorphized versions of objects and animals, combine irrelevant concepts in reasonable ways, and give variation to any user-provided images, we witnessed such rapid technological advancement left many visual artists disoriented in leveraging LTGMs more actively in their creative works. Our goal in this work is to understand how visual artists would adopt LTGMs to support their creative works. To this end, we conducted an interview study as well as a systematic literature review of 72 system/application papers for a thorough examination. A total of 28 visual artists covering 35 distinct visual art domains acknowledged LTGMs' versatile roles with high usability to support creative works in automating the creation process (i.e., automation), expanding their ideas (i.e., exploration), and facilitating or arbitrating in communication (i.e., mediation). We conclude by providing four design guidelines that future researchers can refer to in making intelligent user interfaces using LTGMs.
- to appear