
Measuring the Validity of Clustering Validation Datasets
Hyeon Jeon, Michaël Aupetit, DongHwa Shin, Aeri Cho, Seokhyeon Park, and Jinwook Seo / 2025
PARTICIPANTS
- Hyeon Jeon, Seoul Nationl University
- Michaël Aupetit, QCRI, Hamad Bin Khalifa University
- DongHwa Shin, Kwangwoon University
- Aeri Cho, Seoul National University
- Seokhyeon Park, Seoul National University
- Jinwook Seo, Seoul National University
ABSTRACT
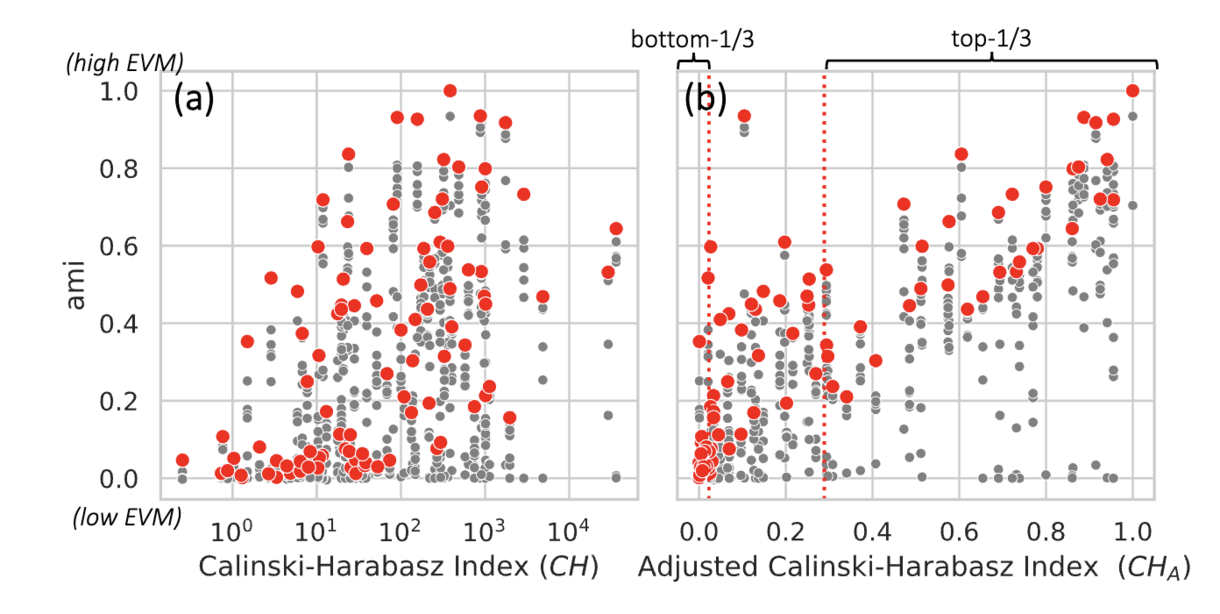
Clustering techniques are often validated using benchmark datasets where class labels are used as ground-truth clusters. However, depending on the datasets, class labels may not align with the actual data clusters, and such misalignment hampers accurate validation. Therefore, it is essential to evaluate and compare datasets regarding their cluster-label matching (CLM), i.e., how well their class labels match actual clusters. Internal validation measures (IVMs), like Silhouette, can compare CLM over different labeling of the same dataset, but are not designed to do so across different datasets. We thus introduce Adjusted IVMs as fast and reliable methods to evaluate and compare CLM across datasets. We establish four axioms that require validation measures to be independent of data properties not related to cluster structure (e.g., dimensionality, dataset size). Then, we develop standardized protocols to convert any IVM to satisfy these axioms, and use these protocols to adjust six widely used IVMs. Quantitative experiments (1) verify the necessity and effectiveness of our protocols and (2) show that adjusted IVMs outperform the competitors, including standard IVMs, in accurately evaluating CLM both within and across datasets. We also show that the datasets can be filtered or improved using our method to form more reliable benchmarks for clustering validation.
Website
Publications
- Hyeon Jeon, Michaël Aupetit, DongHwa Shin, Aeri Cho, Seokhyeon Park, and Jinwook Seo, "Measuring the Validity of Clustering Validation Datasets", [PDF], IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)